Introduction
What is Attributed Graph Clustering?
Attributed Graph Clustering (AGC) is the task of partitioning nodes in a graph into disjoint clusters based on both:
Graph Structure: Connectivity patterns encoded in the adjacency matrix
Node Attributes: Feature vectors associated with each node
Unlike node classification, AGC operates in an unsupervised setting without ground-truth labels. This capability makes it indispensable for industrial applications, such as detecting communities in social networks, identifying fraud rings in transaction networks, or segmenting users for personalized recommendation.
The ECO Framework
PyAGC organizes all clustering methods under the Encode-Cluster-Optimize (ECO) framework:
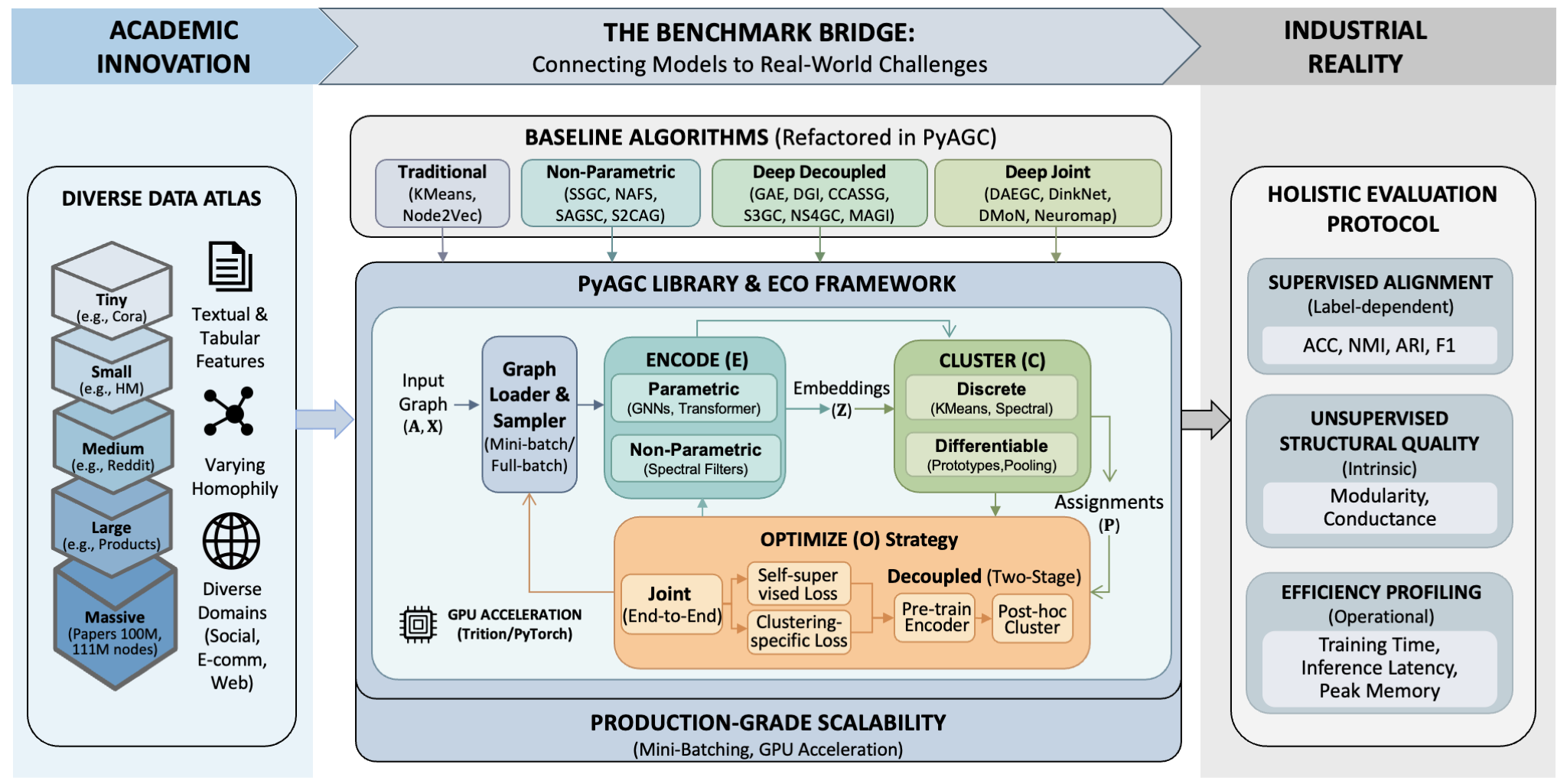
Components
1. Encoder: Transforms graph structure and attributes into latent representations
Parametric: GCN, GAT, GraphSAGE, SGFormer
Non-parametric: Graph filters, adaptive smoothing
2. Cluster Head: Projects embeddings to cluster assignments
Differentiable: Softmax pooling, prototype-based
Discrete: KMeans, Spectral Clustering, Subspace Clustering
3. Optimization Strategy: Defines training objectives
Joint: End-to-end training with clustering loss
Decoupled: Pre-train encoder, then apply clustering
Supported Algorithms
PyAGC implements 20+ state-of-the-art methods:
Traditional Methods
KMeans (attribute-only)
Node2Vec (structure-only)
Non-Parametric Methods
SGC, SSGC, NAFS, SAGSC, S2CAG, MS2CAG
Deep Decoupled Methods
GAE, ARGA, DGI, CCASSG, GBT, S3GC, NS4GC, MAGI
Deep Joint Methods
DAEGC, DinkNet, MinCut, DMoN, Neuromap, GCSBM
Design Philosophy
Modularity: Swap encoders and cluster heads without changing core logic
Scalability: Mini-batch support for billion-scale node graphs
Reproducibility: Configuration-driven experiments with fixed random seeds
Extensibility: Clean abstractions for implementing new methods
Quick Example
import torch
from torch_geometric.data import Data
from pyagc.data import get_dataset
from pyagc.encoders import GCN
from pyagc.models import DGI
from pyagc.clusters import KMeansClusterHead
from pyagc.metrics import label_metrics
# Load dataset
x, edge_index, y = get_dataset('Cora', root='data/')
data = Data(x=x, edge_index=edge_index, y=y)
# Setup device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Create encoder and model
encoder = GCN(
in_channels=data.num_features,
hidden_channels=512,
num_layers=1
)
model = DGI(hidden_channels=512, encoder=encoder).to(device)
# Train
data = data.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(200):
loss = model.train_full(data, optimizer, epoch, verbose=(epoch % 10 == 0))
# Generate embeddings
model.eval()
with torch.no_grad():
z = model.infer_full(data)
# Clustering
n_clusters = int(y.max().item()) + 1
kmeans = KMeansClusterHead(n_clusters=n_clusters)
clusters = kmeans.fit_predict(z)
# Evaluate
metrics = label_metrics(y, clusters, metrics=['NMI', 'ARI'])
print(f"NMI: {metrics['NMI']:.4f}, ARI: {metrics['ARI']:.4f}")
Next Steps
Follow the quickstart tutorial for a hands-on introduction
Explore the ECO framework in detail
Learn about scalability features for large graphs